基于神经网络的计算机视觉算法因为具有较好的鲁棒性而被大家所喜爱。本文将简单介绍使用 Intel 的 OpenVINO 来进行视觉神经网络运算的应用。
OpenVINO 是一套深度学习工具库,它可以对你的神经网络模型进行优化、使用他们的推理引擎加速运算。

在使用 OpenVINO 之前,我们需要先有一个能用的模型,因此,本文的前半部分将讲述普通的神经网络模型的制作,后半部分再讲述如何把它与 OpenVINO,以及我们的项目结合。
本文将以 ultralytics 实现的 YOLOv5 神经网络算法识别 RoboMaster比赛中机器人的装甲板为例。
0x01 素材整理
转码
我们的素材一般由安装在机器人上的工业相机录制。由于编码问题,会导致录制出来的文件比较大,浪费硬盘存储空间。
你可以使用 ffmpeg -i record_x.avi record_x.mp4 这样的命令将视频转为 H.264 MP4 视频,一般情况下能在画质不会降低很离谱的情况下节省 95% 左右的空间。
存储与备份
这一部分放到前面来说。其实不仅仅对于素材,包括数据集文件、模型结果和源码,都需要特别注意。每个步骤产生的文件都会花费一定的成本,有些文件消失了就没有机会重新找回来了。所以,在你决定使用某个贵重文件前,最好都应该先备份,再使用。
一个比较妥善的方法是本地+远程备份。本地备份是指将文件拷到U盘或者移动硬盘上。但是较小的U盘可能会因为各种原因失踪,移动硬盘有可能会因为碰撞而损坏。所以,你最好再把文件复制一份到诸如百度云这样的网盘上。虽然它下载速度不快,但是如果你误删了文件,至少有个办法可以让它回来。
剪辑
我们的场景是对视频进行数据标注,但我们的视频里与我们要标注的内容有关的帧其实不是很多。过多的无关帧会给我们下一步的标注带来麻烦,所以在开始标注之前,我们需要对视频进行剪辑,只保留我们想要的部分。
对于剪辑这一块,你可以使用专业的 Adobe Premiere Pro, 也可以找一些免费开源的软件。
本人随便找了个叫 OpenShot Video Editor 的软件举个例子。
打开软件后,把你的视频拖到软件底部的时间线上。
播放视频,在你想剪的地方点击添加标记。
当你觉得有效的帧数已经足够的时候,用分割工具把之前标记过的视频段剪开,删除不要的部分,把视频在一起放到开头。
最后一步是导出,这个软件的导出视频功能在 文件 > Export Project > 导出视频。
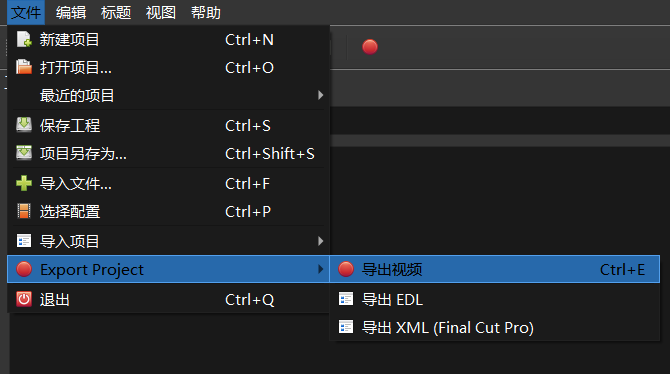
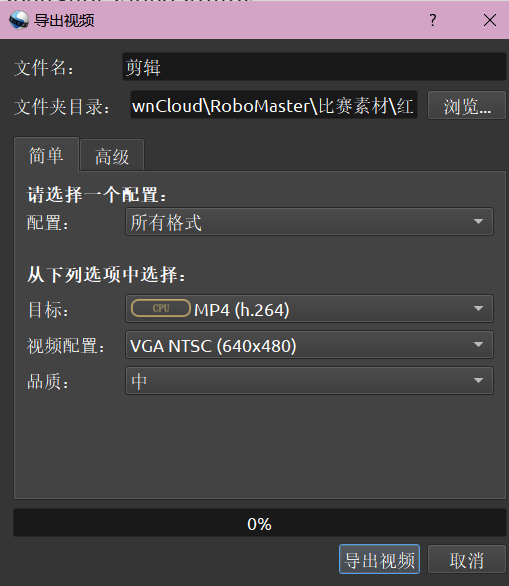
导出时一般需要设置一些参数,比如说导出的视频编码,以及视频尺寸(配置)。
这里我们使用 MP4(h.264) 和 640x480 大小的分辨率,因为这样的视频既不会丢失我们想要识别目标的特征,又可以让文件体积变小。
0x02 数据标注:CVAT
为了让我们的神经网络能知道什么是我们感兴趣的东西,它叫什么名字,我们需要先手工标注一些数据给它,做成让它学习用的数据集。
数据集一般由标签和图片组成。标签是一段文本,用来告诉神经网络图片中的东西叫什么名字。
数据标注是最让人痛苦的环节,但也是最重要的环节。这个神经网络在我们项目中能不能达到论文写的预期效果,和你的数据集有着非常大的关系。如果你的数据集敷衍了事,那么神经网络产生的结果也是非常敷衍的。
对于 AI 项目来说,成功的最重要的影响因素之一是你可以使用的“优质数据”的数量。
所谓的计算机视觉应用的“优质数据”是指:
- 每个图片/标注都有一个恰当的标签。
- 每个边界框或多边形都紧致地包围着要训练的物体。
数据标注的软件有很多,你在这里就可以看见很多。
本人选择的是 OpenVINO Toolkit 下的 CVAT。选择它的原因是它支持自动化插值、多人同时标注、跨平台,而且它也没有传说中的那么难。开始的时候你会觉得不太习惯,但标注得多了你就能发现它的使用技巧。
CVAT 是一个 Web 程序,所以你只需要有一个浏览器就能用。他们有一个官方的演示型网站,在 cvat.org。如果你单纯想试试,可以直接打开,注册一个账号就能使用。
官方手册地址:https://openvinotoolkit.github.io/cvat/
安装
对于一个团队来说,安装一个 CVAT 实例就可以了。
本节参考:https://openvinotoolkit.github.io/cvat/docs/administration/basics/installation/
CVAT 被封装在了一个 Docker 环境里,所以首先你要安装 Docker,如果你使用 Ubuntu,你的 Ubuntu 版本至少得是 18.04。
sudo apt-get update
sudo apt-get --no-install-recommends install -y \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get --no-install-recommends install -y docker-ce docker-ce-cli containerd.io
# 安装好之后,把你的用户添加到 docker 组中,以便使用 docker 有关的命令
sudo groupadd docker
sudo usermod -aG docker $USER然后你需要安装 docker-compose,这是一个管理 docker 容器之间互相交互的程序。
sudo apt-get --no-install-recommends install -y python3-pip python3-setuptools
sudo python3 -m pip install setuptools docker-compose
到这里才是安装 CVAT 的步骤。首先,搞到源码。
sudo apt-get --no-install-recommends install -y git
# 如果你的网络访问 GitHub 比较困难,可以用换下面这个命令
# git clone https://hub.fastgit.org/opencv/cvat
git clone https://github.com/opencv/cvat
cd cvat首次启动时,docker 会下载容器镜像,这可能需要比较长的时间。
docker-compose up -d上面那个命令执行完之后,说明容器已经启动了,你的 CVAT 也会在几秒之后可以访问。打开 http://localhost:8080,你就可以看见你的 CVAT。先别急着登录,在首次使用之前,你需要执行下面的命令来创建一个管理员用户。
docker exec -it cvat bash -ic 'python3 ~/manage.py createsuperuser'下面这个命令可以帮你安装好 Chrome 浏览器。
curl https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
sudo sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
sudo apt-get update
sudo apt-get --no-install-recommends install -y google-chrome-stable如果你希望你的 CVAT 可以被其他电脑访问到,在启动 CVAT 之前,你需要先设置环境变量 CVAT_HOST 为访问的域名或者 IP。下面几个命令也许你会用得到:
# 在你的 CVAT 目录下
docker-compose down # 关掉 CVAT
export CVAT_HOST=192.168.1.3 # 然后大家在地址栏输入 192.168.1.3:8080 来访问
docker-compose up -d # 启动 CVATCVAT 还可以设置一个公用位置来读取你的素材。
你需要编辑 docker-compose.yaml,改成这样:
version: '3.3'
services:
cvat:
environment:
CVAT_SHARE_URL: 'Mounted from /mnt/share host directory'
volumes:
- cvat_share:/home/django/share:ro
volumes:
cvat_share:
driver_opts:
type: none
device: /mnt/share # 在这台电脑上的位置
o: bind把你的素材放到里面, 你就可以在创建任务的时候直接选择那个文件,而不用手动上传。
准备标注
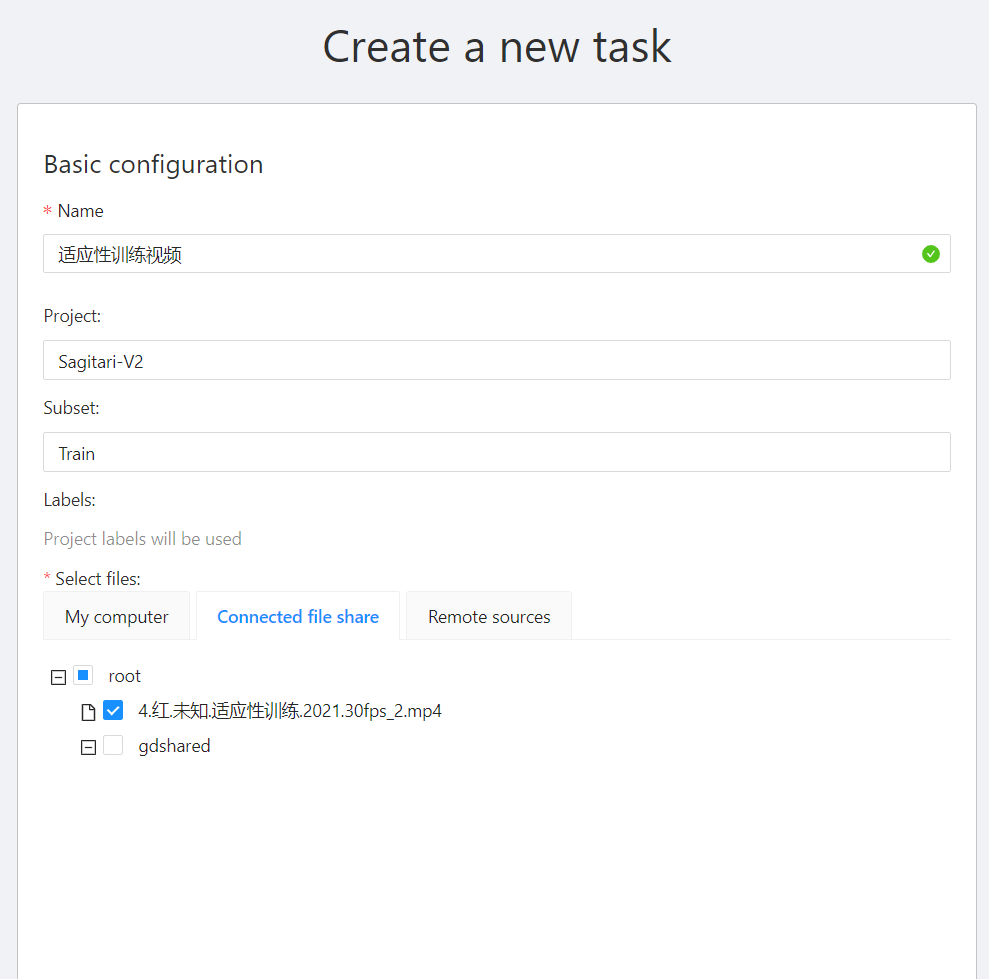
登录 CVAT 之后,你会发现它有 Projects 和 Tasks 两个标签页。 我们先创建一个 Project。
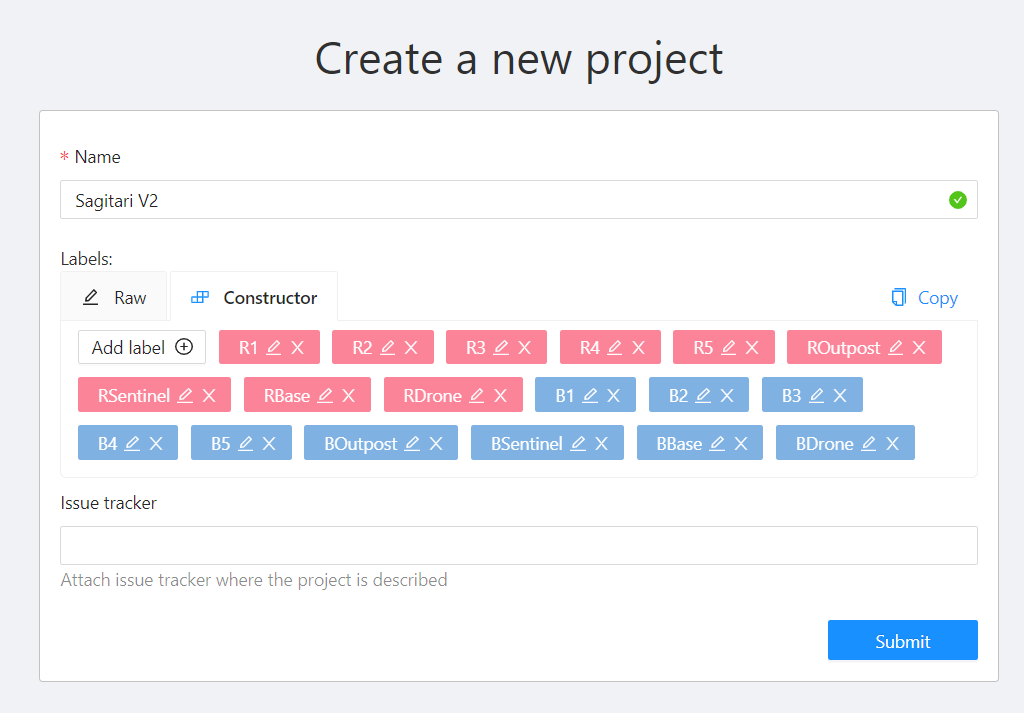
然后去创建 Task 的时候,我们就可以选择之前那个 Project。
Subset 这个项可以选择 Train 、 Test和 Validation。说明这个task生成的训练集是做什么用的。
打开 Advanced configuration,下面也有一些东西需要你注意。
Copy data into CVAT如果你的素材文件待会要删掉了,或者它是网络挂载的(比如说 rclone),那么记得勾这个选项。Image quality没必要太高。 CVAT 会把你的视频剪成一张张图片再进行标注。如果你的图片质量太高,到时候会导出好几 GB 的数据集文件。这会导致…… 不方便转移。Segment size会把你的视频按那个数字分成不同的 jobs。然后大家就可以找还没完成的 jobs 去标注了。
最后它大概是这样的:
之后点击 Submit 就可以啦!
标注
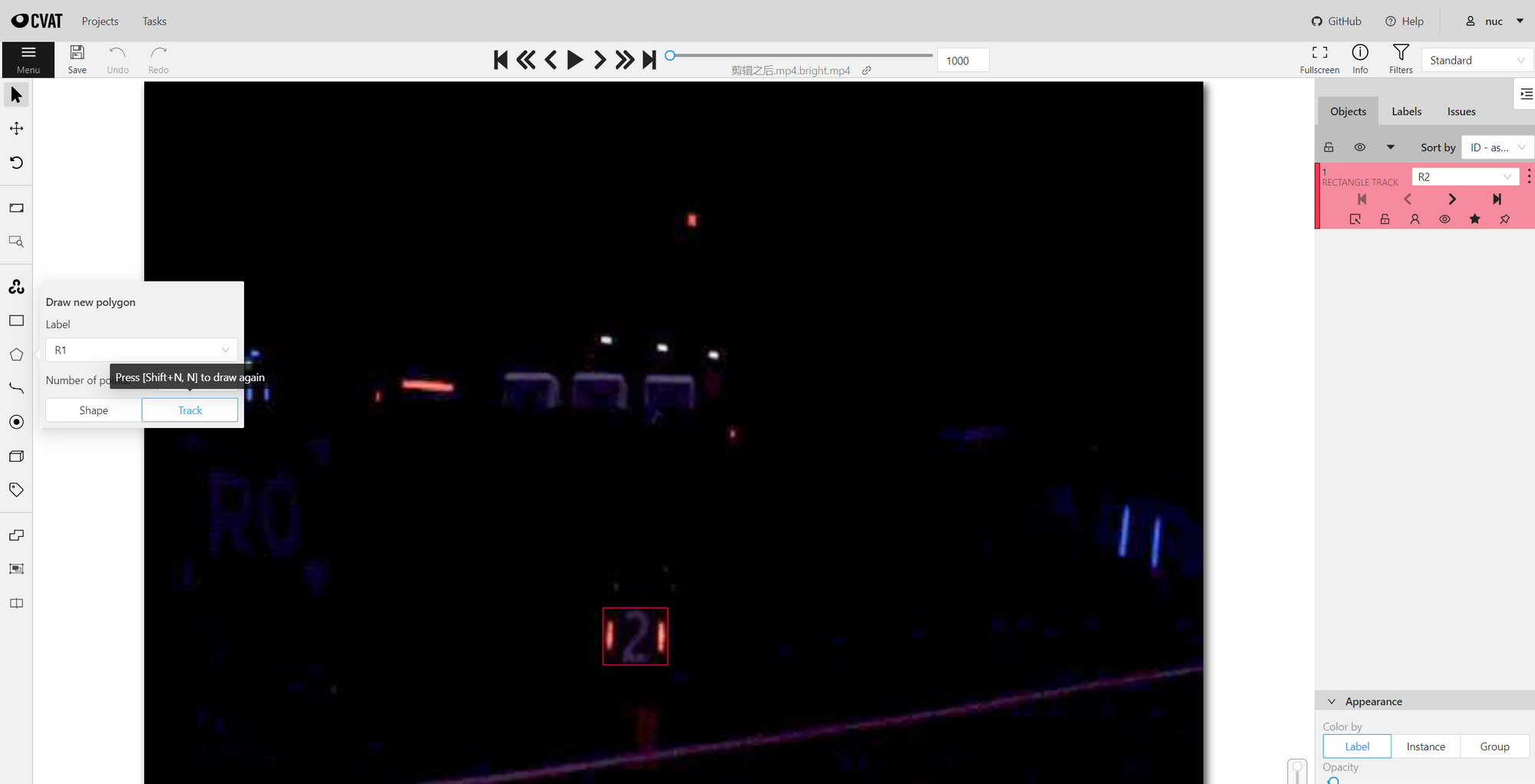
在这一步,你最好主要一下这些事:
- 快捷键很好用。CVAT 很贴心地把快捷键写在每个按键的提示上了。使用快捷键可以加快标注流程。
- 对移动的目标使用 Track。 Track 和 Shape 的区别是, Shape 的框在下一帧会消失,而 Track 不会。如果目标在图片里是连续移动的,那么你可以不用每一帧都调整框的位置!!继续往下切几帧,然后再调整位置。接下来往回切,你会发现你没调整的帧也会自动跟着改变。
- 如果 Track 的目标消失了,点击
Switch Outside Property。 - 记得随手保存一下。
当前的 job 完成之后,点菜单的 Finish the job 来标记完成这个job。
如果你找了工具人来帮你标注,而你不能保证他的质量,你可以让它选择 Request a review,这样你就可以自己再过一遍,以防万一。数据集里掺屎是一件非常痛苦的事情。
导出
标注页面和 Task 页面都可以 Export as a dataset。如果你要导出整个 Task 的数据集,那就在 Task 页面的 Action 下选 Export as a dataset。

你可以选择导出的格式。对于 YOLOv5 来说,我们选 YOLO 就可以了。
附 - 数据集格式转换:Roboflow
如果你手上有一份其他格式的数据集,让你不方便使用,那要怎么快速转换成你能用的格式呢?
这个时候我们可以使用 Roboflow 这个平台。
把数据集里的标签文件和图片文件放进去,它就可以自动读取。在 Export 的时,你可以选择你想要的格式。
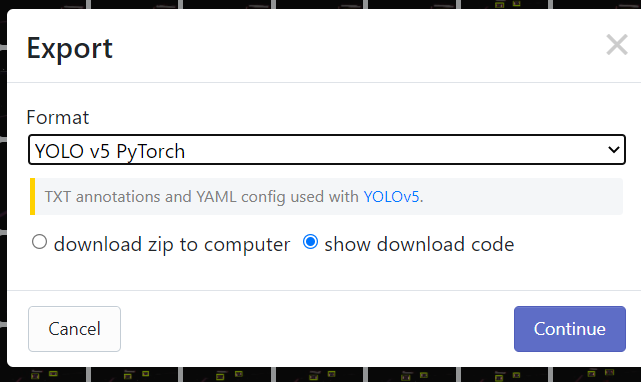
show download code 可以生成让 Jupyter Notebook 直接执行的代码,这对于下一步如果使用 Google Colab 进行训练来说非常方便。
0x03 模型训练
如果说数据标注让人痛苦,那么模型训练就是让机器痛苦。
模型训练是一个耗时很长的事情,你有可能会遇到程序爆炸、显存爆炸等各种白给的情况。它对机器的配置也有要求。一般来说 GPU 训练的速度会比 CPU 训练的速度要快一些,如果你的电脑配置不够,那么你有两个选择:
白嫖 Google Colab
Google Colaboratory 是 Google 提供的一个在线编辑执行环境。它是一个运行着 Jupyter Notebook 的虚拟机。它可以让你在网页里写代码,然后点击就可以运行。运行结果和代码、说明等都会以 .ipynb 格式的文件保存,叫笔记本。别人打开的时候可以直接看见你的运行结果。
最重要的是, Colab 可以提供免费的 GPU 服务器让你实验你的神经网络项目。
首先,你需要有一个 Google 账号,然后打开下面这个链接:https://colab.research.google.com/drive/11LiUAPeFOlMwtp99aD8D9bOeVViuHDWu
这是本人之前测试用的一份笔记本,它是从 YOLOv5 官方提供的那份笔记本简化而来的。你可以把代码中读取训练集的部分换成自己的链接,其他地方应该不用修改太多。

Colab 可以和你的 Google Drive 传输文件。你可以点击左边菜单的 装载 Google 云端硬盘。
根据它的提示来。
临时租用 GPU 服务器
矩池云是一个可以低价租到 GPU 服务器的地方。它提供 SSH 和 HTTP 两种访问方式。
通过 SSH 访问,操作就和日常使用 Linux 系统差不多。
通过 HTTP 访问,它会提供一个 Jupyter Notebook,操作就和上面使用 Colab 差不多。
你可以在这里学习如何使用他们的产品:https://www.matpool.com/supports/doc-img-recognition-case/
在这里选择服务器:https://www.matpool.com/host-market/gpu
你可以使用我的邀请码 Y1LZPj7h6iO0AJB ,可以奖励代金券。、
使用攻略
- 如果你是学生,可以在这里申请学生认证。认证需要1-2个工作日的时间,通过之后可以得到一些优惠。
- 首次注册成功后去微信公众号绑定你的账号,可以获得5元代金券。
- 在选择配置的时候,可以在系统镜像中选择你会用到的库,这样可以节省时间。
- 如果你选了系统镜像,还可以勾选 Tmux,这样通过 ssh 登录之后将会自动连接到一个 Tmux 会话中,它可以让你的任务在 ssh 断开的情况下继续执行。
下单之后,等待系统启动完成,你可以看到这样的画面:
此时就可以用 ssh 或者 VSCode 连接了。
首次登录时别忘了使用他们的专有工具来更换 apt 和 pip 的镜像源:
无论是使用 Colab 还是租用 GPU 服务器,你都可以执行 nvidia-smi 来查看当前服务器的 GPU 状态。
训练
有关模型训练的步骤我已经写在了 Colab 的那个链接里,
下载 YOLOv5的源码,读取训练集,训练、验证。
使用 Roboflow 导出的训练集压缩包包含一个 data.yaml 文件,它的内容很简单:
train: ../train/images # 用来训练的图片
val: ../valid/images # 用来验证的图片 validation。如果没有的话,就和 train 一样吧
nc: 1 # 标签的个数
names: ['red_5'] # 标签名字如果你使用 CVAT 导出数据集,可能要自己来写这个文件,你也可以在 yolov5/data 下面找到他们提前写好的一些文件。
留意一下 训练之后的输出:
Optimizer stripped from runs/train/exp/weights/last.pt, 42.4MB
Optimizer stripped from runs/train/exp/weights/best.pt, 42.4MB这是生成的权重文件,人类知识的结晶。best.pt 就是训练最好的一次权重, last.pt 是最后一次训练的权重,接下来,我们要用的就是这个东西。
你还应该注意的是 runs/train/exp/result.png 里的图标。 precision 和 recall 是模型训练结果的重要指标。它越接近 1, 你的模型越准确。
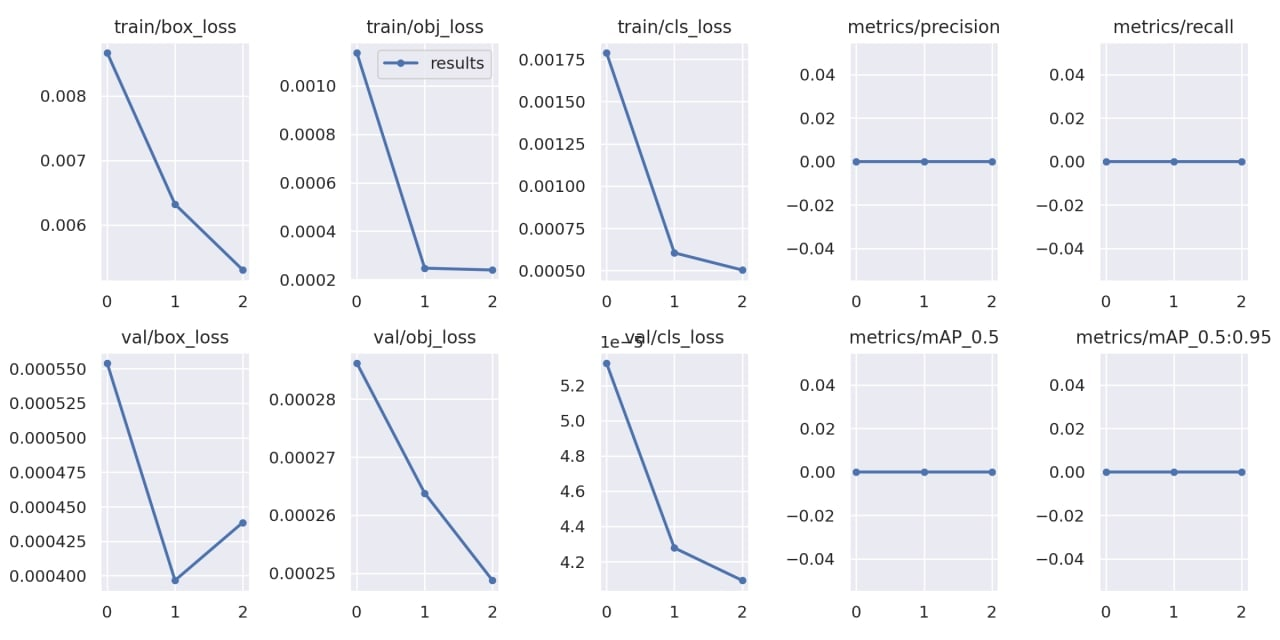
如果你的模型看起来训练得很糟糕,可以考虑换一个预训练模型、增加 epochs 等。
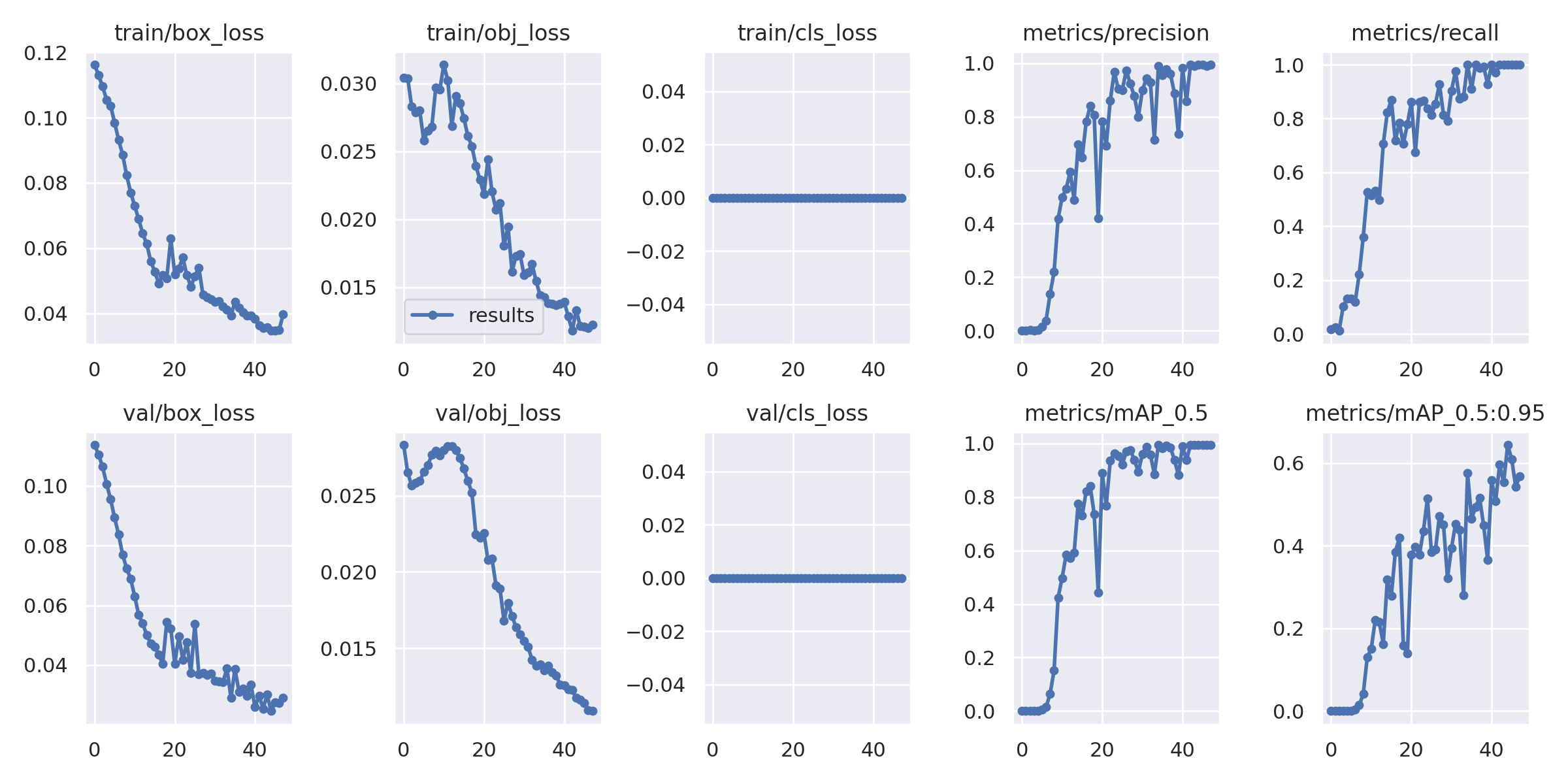
0x04 模型转化
训练得到的模型格式为 . pt 格式,为了实现 OpenVINO 部署,需要首先转换为 . onnx 的文件格式,之后再转化为 OpenVINO 需要的 . xml 和 . bin 的文件格式。
.pt 转 .onnx
这部分可以直接使用 Yolov5 自带的转换脚本,由于 OpenVINO2021.1 还为未支持 opset=12, 需要指定 opset 为 10.
python export.py --weights runs/train/exp/weights/best.pt --img 640 --batch 16 --opset 10 # export at 640x640 with batch size 16然后你就可以在 runs/train/exp/weights/best.onnx 这里找到生成的文件。
.onnx 转 OpenVINO 格式
首先, 你需要安装 OpenVINO,安装的方式可以参考这里: https://docs.openvinotoolkit.org/2021.4/openvino_docs_install_guides_installing_openvino_images.html
接下来是安装模型转化工具的依赖。
sudo bash /opt/intel/openvino/deployment_tools/model_optimizer/install_prerequisites/install_prerequisites_onnx.sh之后,你就可以用下面的命令来转换上一步生成好的 .onnx 模型为 OpenVINO 食用的 .xml 和 .bin 格式文件。
python /opt/intel/openvino/deployment_tools/model_optimizer/mo_onnx.py --input_model .onnx文件路径 --output_dir 转换后的输出路径0x05 模型部署
请参考:http://www.giantpandacv.com/部署优化/AI 部署及其它优化算法/OpenVINO/c%2B%2B实现yolov5的OpenVINO部署/#openvino
